We introduce ![]() Husky-v1, a holistic, open-source language agent that learns to reason over a unified action space to address a diverse set of complex tasks involving numerical, tabular, and knowledge-based reasoning.
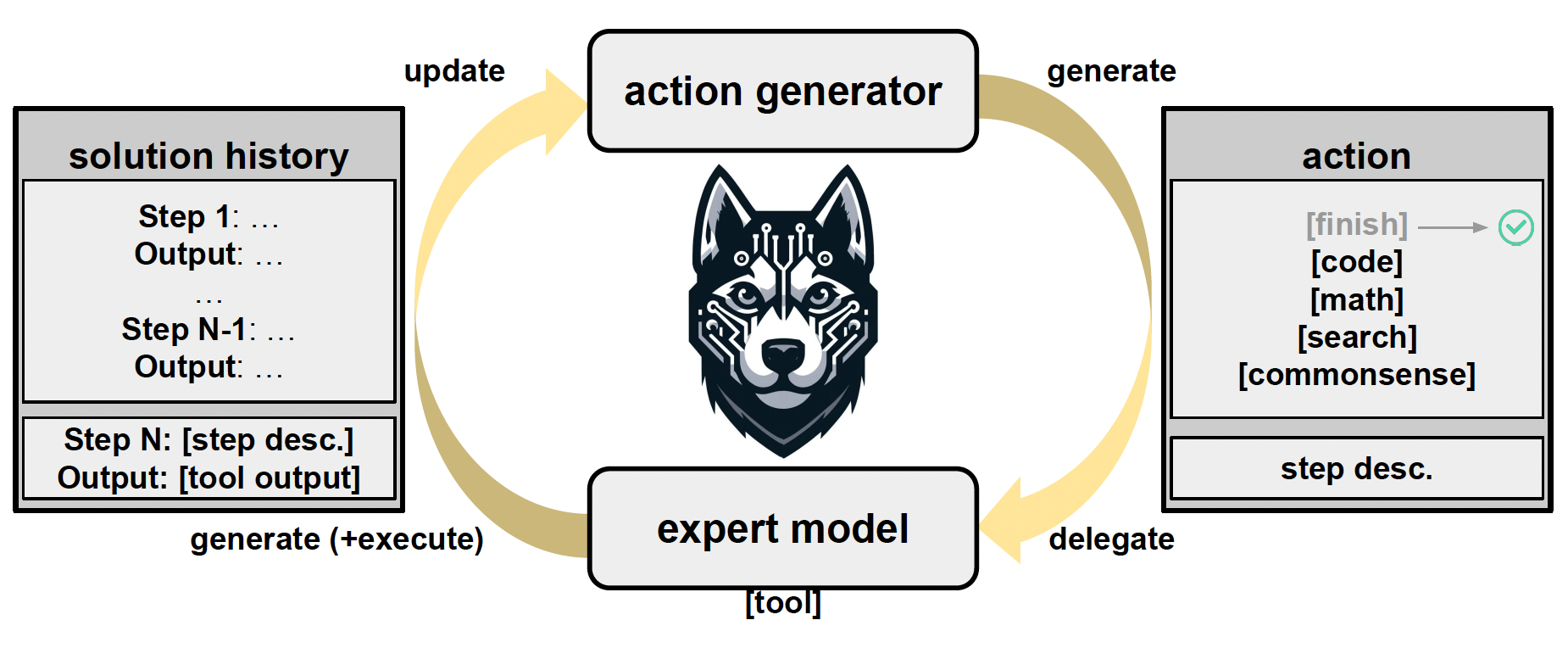
Husky iterates between two stages: 1) generating the next action to take towards solving a given task, and 2) executing the action using expert models and updating the current solution state.
Husky-v1 uses a code generator, a query generator and a math reasoner as expert models.
Husky-v1, a holistic, open-source language agent that learns to reason over a unified action space to address a diverse set of complex tasks involving numerical, tabular, and knowledge-based reasoning.
Husky iterates between two stages: 1) generating the next action to take towards solving a given task, and 2) executing the action using expert models and updating the current solution state.
Husky-v1 uses a code generator, a query generator and a math reasoner as expert models.
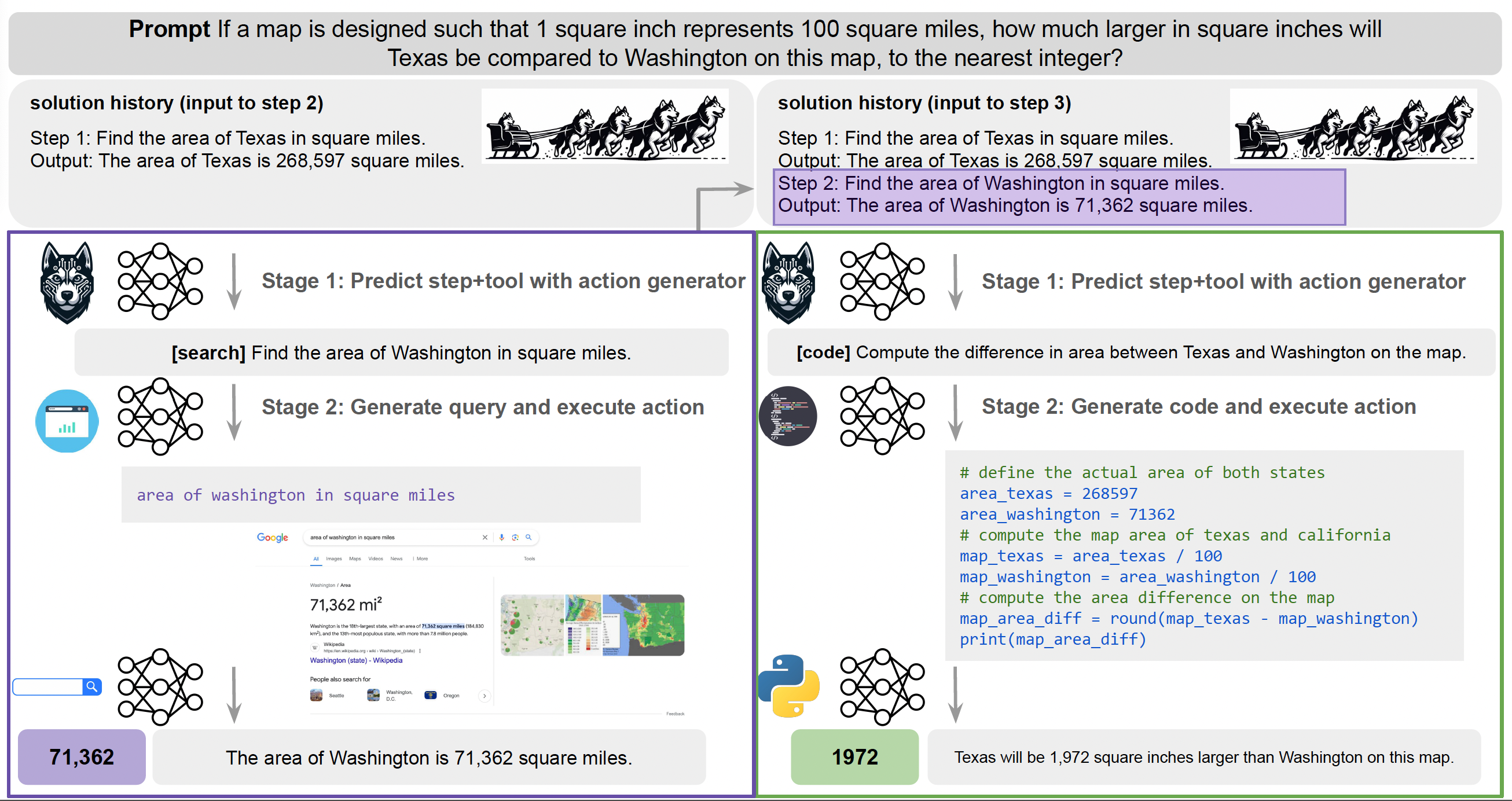
One significant feature of Husky is its unified action space, where the tools it utilizes are agnostic to the task being addressed (see below). By doing so, we maintain Husky's generalizability across numerical, tabular and knowledge-based reasoning tasks.

Husky-v1 uses the following action space:
All modules in Husky-v1 are trained using synthetic data. We use a teacher LM to generate tool-integrated solution trajectories for each question in the training set. Then, we extract different components of the solution trajectories to build training data for each of the modules in Husky, including the action generator and the expert models.

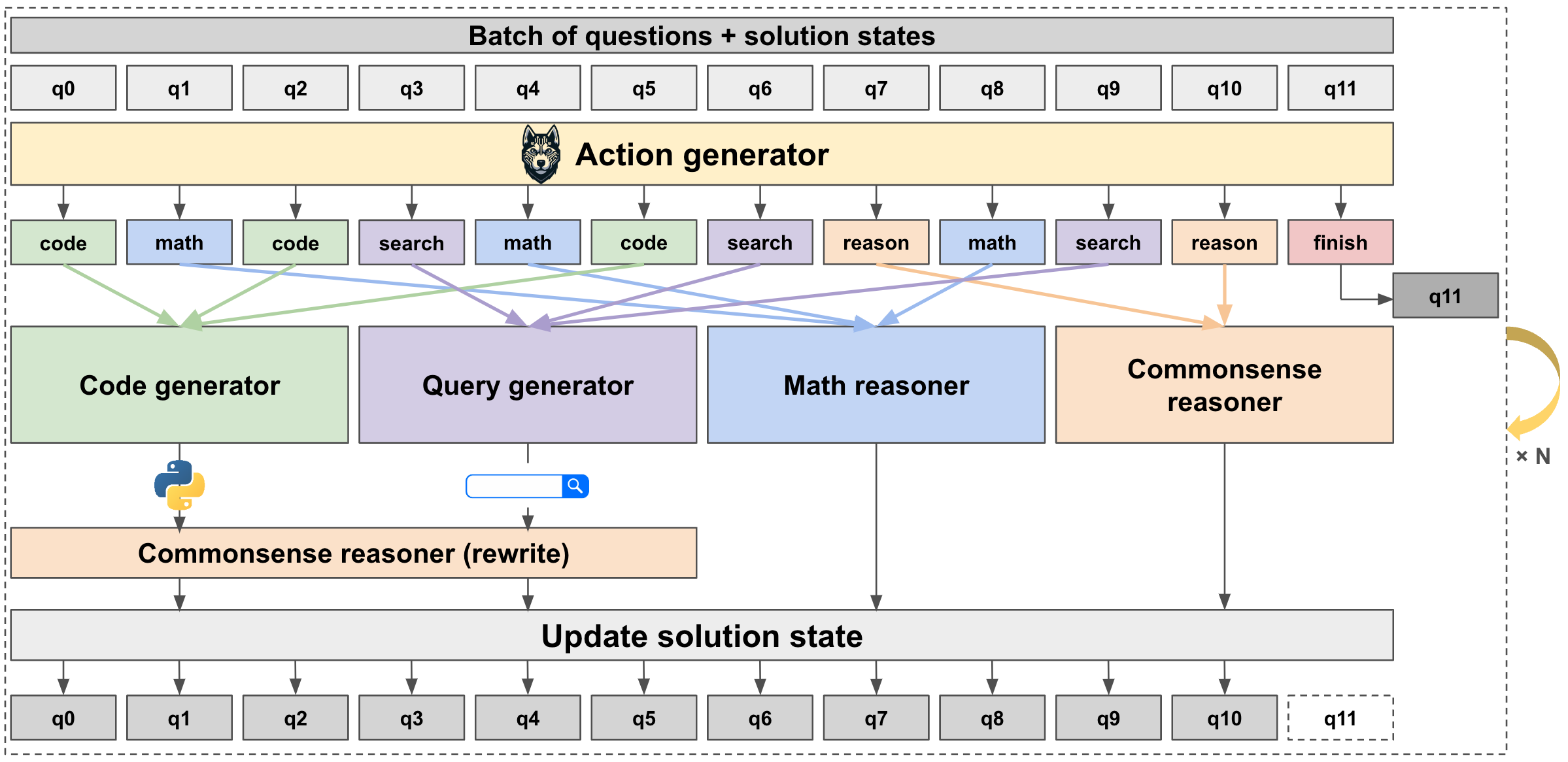
Contrary to implementations for previous language agents, Husky performs inference by batch processing all inputs and executing all tools (expert models) in parallel. We jointly predict the next step and associated tool with the action generator over a batch of questions and their solution states, delegate the outputs to their corresponding expert model, execute the models and update our solution state based on the outputs from the expert models. Then, we repeat this process over multiple iterations until the agent reaches the final answer for all questions.
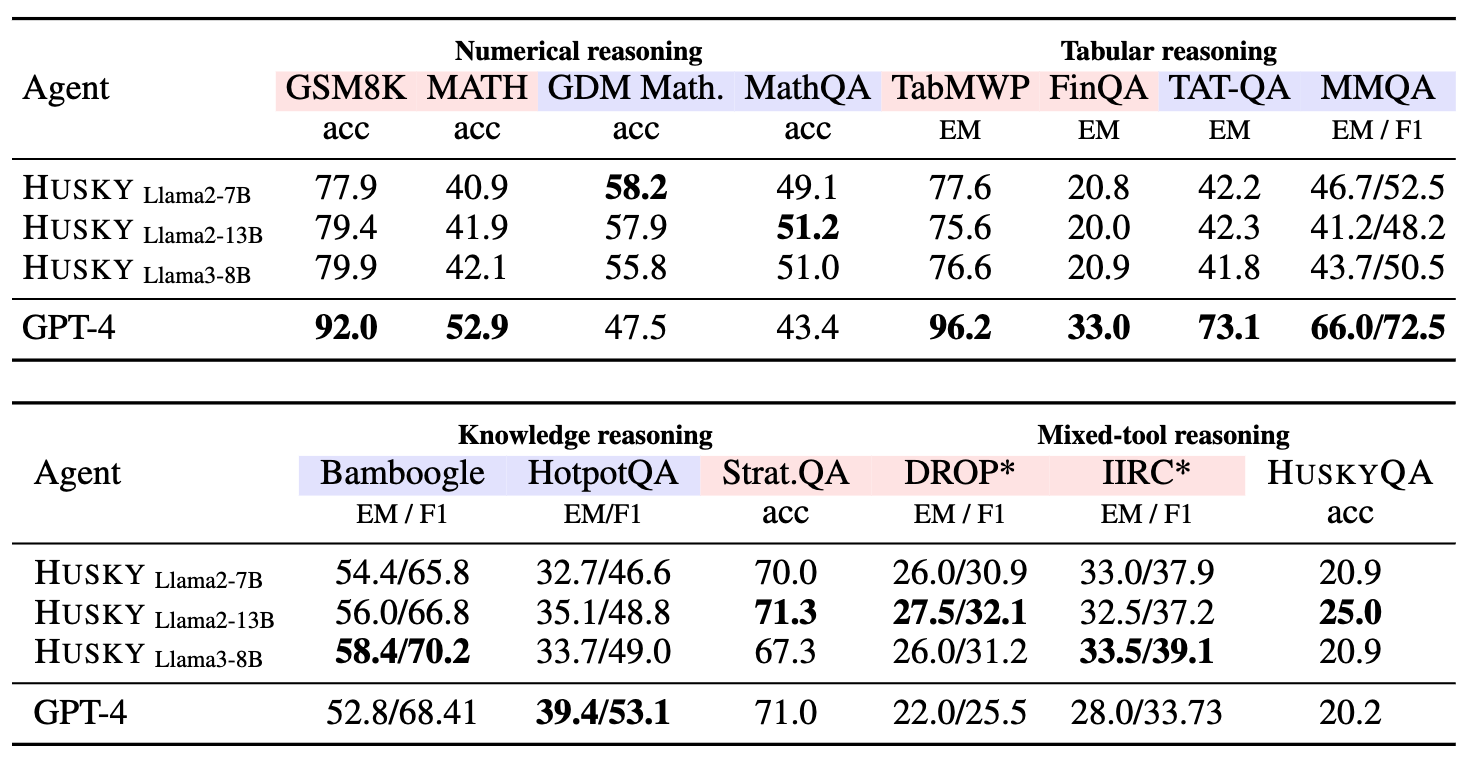
We evaluate Husky-v1 on a set of 14 different evaluation tasks. Husky-v1 outperforms other language agents consistently across our evaluation tasks, and even outperforms GPT-4-Turbo on the mixed-tool reasoning tasks.
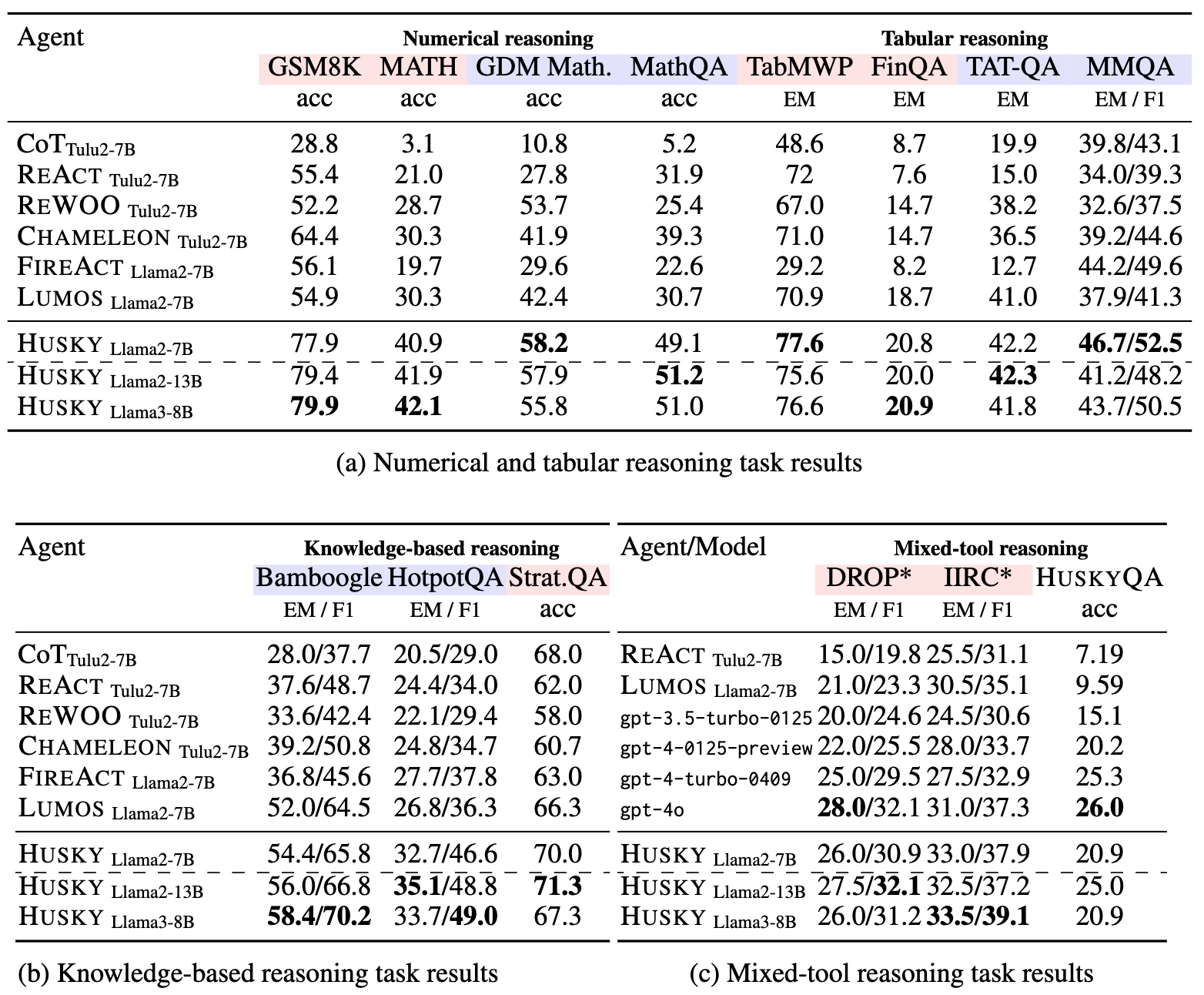
We compare Husky-v1's performance with GPT-4-Turbo (gpt-4-0125-preview for all tasks except GSM-8K and MATH, which use gpt-4-0613) across the same set of evaluation tasks. Notably, Husky-v1 outperforms GPT-4-Turbo on out-of-domain math evaluation tasks (Google DeepMind mathematics, MathQA) and mixed-tool reasoning tasks (DROP*, IIRC*, HuskyQA).
We measure Husky-v1's performance when the action generator is trained on specific task domains. As shown below, the joint action generator trained over all task categories (numerical, tabular, knowledge-based, mixedl-tool) does not incur much performance loss. Our results indicate that subsequent versions of Husky can de adapted to a wider variety of tasks by scaling the action space as well as the diversity of the expert models.

Refer to our GitHub repo to get started with using Husky-v1. Download the modules for Husky-v1, as well as our mixed-tool evaluation sets, from our HuggingFace repo.
Please contact Joongwon (Daniel) Kim at jwonkim at cs dot washington dot edu.
@misc{kim2024husky,
title={Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning},
author={Joongwon Kim and Bhargavi Paranjape and Tushar Khot and Hannaneh Hajishirzi},
year={2024},
eprint={2406.},
archivePrefix={arXiv},
primaryClass={cs.CL}
}